
Hello. I'm one of the co-founders of Pure Adapt, Inc, located in Albany, NY. Our primary business is Detailed Image, an online retailer of high quality car care supplies. We do almost everything in-house: design, programming, marketing, inventory management, warehouse operations, and more. Since our inception in 2006 we've bootstrapped all of our growth internally. No outside funding, just hard work and reinvesting profits.
I spend most of my days programming for Detailed Image, analyzing data, and overseeing our web marketing initiatives. But like a lot of business owners I also spend quite a bit of time on HR, customer service, and anything else that's needed. I have two partners, Mike and Greg, who do a tremendous job managing the other aspects of the business.
We've operated from our warehouse in Guilderland Center, NY since 2008. It started out as a 5,200 sq-ft space, which we then expanded in 2016, 2019, and 2021 to over 22,000 sq-ft to accommodate our growth. We have an exceptional staff of full-time employees, part-time employees, and contractors that help make the magic happen. Every day we strive for fantastic customer service, a great website, efficient warehouse operations, a strong culture, and building a company for the long haul.
The Albany Business Review named us one of the Best Places to Work in the Capital Region. Our salaried employees and our hourly employees receive their health insurance premiums paid in full, paid time off, and matching contributions to our retirement plan. We were also named to their list of the Fastest-Growing Companies in the Albany area from 2016 to 2019. And for five straight years from 2015 to 2019 we were named to the Inc. 5000, a list of the fastest growing private companies in America.
Community involvement is important to us. For over 10 years we have offered college scholarships to students of Colonie Central High School through the South Colonie Dollars for Scholars program. I've guest lectured on entrepreneurship at several universities, including SUNY Albany and James Madison, where I co-taught a Web Venturing class to seniors.
I'm originally from Albany. I attended Rensselaer Polytechnic Institute (aka RPI) in Troy, NY and graduated in 2004 with a degree in Industrial & Management Engineering. After college I worked for the razor company Schick in Milford, CT as a quality control engineer in their R&D department for a year before leaving to pursue my own ventures. At the time I had a growing sports collectibles site SportsLizard.com. In early 2006 I left Connecticut and by the end of the year I had connected with my partners to form Pure Adapt.
What I'm currently working on
We're in the process of improving a lot of the infrastructure on Detailed Image. We have legacy code and systems dating back to 2007. Now is the time to make improvements to ensure that we can have a modern, fast, and secure site for another 15+ years.

I'm starting to explore new projects. Things that interest me: static / no-database websites, vanilla CSS and JavaScript, Progressive Web Apps, HTTP/2, and software revenue models that aren't subscriptions.
Recent updates
- 2/5/24 - We recently made a big improvement under the hood to our newsletter system. As was the case with most aspects of our business, when we started we didn't like what was out there when it came to newsletter software. For a short time we used the open source phpList, but eventually decided to build our own system, which we did in 2012. We became experts in SPF, DKIM, DMARC, feedback loops, bounce management, and the like. For a long time, this was perfect. In a relatively low-margin industry, our... Continue Reading
- 6/27/23 - The end of Google's Universal Analytics presented us with an opportunity: is this how we would do analytics and ads if we were starting the business today? The easy choice would have been to upgrade to GA4, keeping third party ad tracking cookies from Google and leaving ad trackers from Meta and Bing untouched. But with Safari and iOS leading the way, most major browsers now block third-party tracking cookies. Chrome is the lone exception, presumably to protect Google Ads, but even they will be... Continue Reading
- 2/3/23 - We recently completed an entire overhaul of our system for quoting shipping rates during checkout. Unlike (literally?) every e-commerce store I am able to study, including major platforms like Shopify, we were not pulling shipping quotes in real-time directly from shipping providers (USPS and FedEx in our case). Originally we did this, but a prolonged FedEx outage on Cyber Monday in 2014, combined with a slower checkout experience while waiting for the rates to load, led us to reconsider our... Continue Reading
- 12/2/22 - For over a decade Black Friday and Cyber Monday were a celebration for us. We'd set sales records. We'd take photos of the towering piles of packages. We'd work weekend shifts and have weekend pickups to make sure everything got out the door on time. I'd often write a blog post celebrating all of this. As our business has evolved and retail in general has scaled back and spaced out the holiday shopping season (remember when stores would open on Thanksgiving?), we've adjusted our approach to... Continue Reading
- 9/20/22 - We recently launched a really nice feature for Detailed Image's shopping cart that filled in some holes in the customer experience and greatly improved our internal shipping data. We're now tracking the status of packages after they leave our warehouse using the FedEx API and USPS API.Previously, our shopping cart's interaction with a customer's order ended after it was shipped. We'd send them an email with a link to the tracking number on FedEx.com or USPS.com. Their order status pages would... Continue Reading
Strengthening Our Newsletter Infrastructure
We recently made a big improvement under the hood to our newsletter system. As was the case with most aspects of our business, when we started we didn't like what was out there when it came to newsletter software. For a short time we used the open source phpList, but eventually decided to build our own system, which we did in 2012. We became experts in SPF, DKIM, DMARC, feedback loops, bounce management, and the like.
For a long time, this was perfect. In a relatively low-margin industry, our email bill was $0. We continued to integrate the system into our shopping cart in ways that would be extremely difficult or impossible with the newsletter services that most companies use. For instance, we can duplicate a previous promotion on the backend by clicking a button and in turn it would schedule products to go on sale, our website to update, a Google Merchant Center promotion, schedule the newsletters, and much more.
However, over the past several years it became increasingly problematic to send increasingly large volumes of email from our server. One example - if our IP was blocked by a service from sending newsletters, it was also blocked from sending transactional emails such as order confirmations.
We set out for a service that would allow us to keep all of our existing systems in place, but send the newsletters themselves through an API call. This proved to be much more difficult to find, and even more difficult to execute.
We chose Elastic Email's Email API and warmed up two dedicated IPs for our newsletters. After months of issues, the system is finally stable. It's now completely separate from our server and our IP that we use for transactional emails. We're much more effective at processing bounces because of how Elastic Email is able to categorize the bounce type prior to passing the information along to our webhook. Monitoring, debugging, and dealing with provider blocks are all much more efficient and straight forward.
Of course, this comes at a cost. But email deliverability is not our core competency or a market differentiator, and lots of companies are now great at it, so it made perfect sense as a small team with limited resources to utilize a partner like Elastic Email so that we can focus on what we do best.
Matomo Analytics + No More Ad Trackers
The end of Google's Universal Analytics presented us with an opportunity: is this how we would do analytics and ads if we were starting the business today? The easy choice would have been to upgrade to GA4, keeping third party ad tracking cookies from Google and leaving ad trackers from Meta and Bing untouched.
But with Safari and iOS leading the way, most major browsers now block third-party tracking cookies. Chrome is the lone exception, presumably to protect Google Ads, but even they will be at some point in 2024. Ad retargeting isn't nearly as useful as it was a few years ago, and ad companies have done a poor job with privacy protections, making retargeting from third-party cookies less ethical in my opinion.
For us, all options were on the table, and thankfully we found what we were looking for with the privacy-focused Matomo Cloud. Matomo isn't just a 1:1 replacement for Google Analytics - there are a ton of useful features that GA does not have. Of course, Matomo is paid software, but the prices are very reasonable and they're a company we're happy to support.
The big question was: could we still run successful ad campaigns? Matomo's advertising conversion export solved the problem. When you click an ad on Google, for instance, Google puts a gclid parameter in the URL. Matomo then exports a list of the gclid's that converted into sales nightly along with the revenue associated with the click. Google knows what clicks convert, but nothing more.
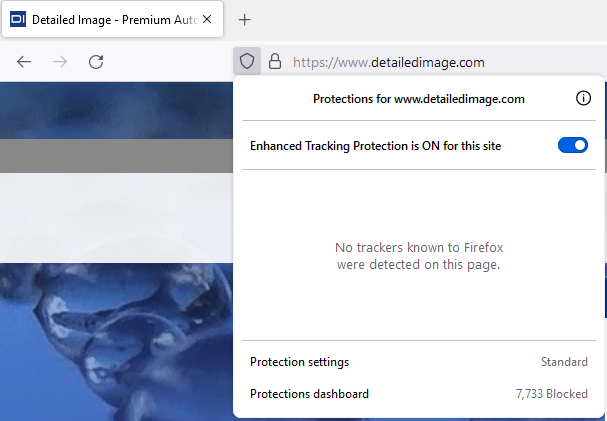
We recently added Matomo to our site and removed tracking code for Google Analytics, Meta, and Bing. Now, when you load our site in a browser like Firefox and click on the privacy shield, you see the glorious message "No trackers known to Firefox were detected on this page." We also got the fringe benefits of improving page speed, simplifying our code base, and an updated and improved Privacy Policy.
This is one of those moves that I really feel good about. We took Google's closure of Universal Analytics and turned it into an opportunity to make a series of improvements that are better for us and better for our customers.
Overhauling Our Shipping Rates System
We recently completed an entire overhaul of our system for quoting shipping rates during checkout. Unlike (literally?) every e-commerce store I am able to study, including major platforms like Shopify, we were not pulling shipping quotes in real-time directly from shipping providers (USPS and FedEx in our case). Originally we did this, but a prolonged FedEx outage on Cyber Monday in 2014, combined with a slower checkout experience while waiting for the rates to load, led us to reconsider our system.
At the time, we decided to "reverse engineer" FedEx's rate quotes and build our own rate quoting system that regularly pinged the API for rates by zip code range and then adjusted for DIM weights, surcharges for residential or rural delivery, and the like. When we added USPS in 2015, we did the same thing.
The system served us well for years, but eventually became unsustainable during the pandemic. The code was already complex, the database tables were massive, and yearly updates were difficult for me and impossible for anyone else. But then both providers started updating their rates and surcharges and formulas much more than once per year for peak time periods and sometimes "just because."
There was also the major downside of lock-in. Adding another service like UPS or DHL or LaserShip would have been extraordinarily difficult because we'd need to first reverse engineer their system as well.
At the same time, my big initiative right now is modernizing and simplifying our 15+ year-old platform to set us up for success in the next decade.
So last year I started working on a system to replace our custom system. The upsides are clear: less code, simpler maintenance, more accurate rates, the ability to add other providers relatively easily. The downsides are also clear: slower load times and reliance on multiple 3rd party services at a critical stage of checkout.
I overcame the biggest hurdles by progressively loading the checkout page - meaning that most of the page still loads immediately, and then 1-2 seconds later the shipping rates and totals fill in - as opposed to waiting for the rates to load first. I also utilized cURL multi-handles in PHP to allow for asynchronous API requests - FedEx and USPS at the same time instead of FedEx first, then USPS as most code would execute - which not only speeds up times now from 2-4 seconds to 1-2 seconds, it allows for multiple services to be added in the future without any loss in speed. And, most importantly, if rates aren't returned within 3 seconds we load rates from a backup system, which is a significantly scaled back and less-accurate version of our prior system, while still being reasonably accurate for our most popular services.
I estimate that the new code base is about 10% of the old system, we'll be able to slim down the database by about a dozen tables, and I was able to eliminate several automated processes that ran all day long on the server.
This week, after almost six months of work, the entirety of the new system went live. So far I'm thrilled. It's working great, our customers should barely notice (I can barely notice even when I'm testing and paying attention to page speed!), and it sets our business up for shipping success in the coming years no matter how we change or the industry changes.
A Smarter Approach to Black Friday
For over a decade Black Friday and Cyber Monday were a celebration for us. We'd set sales records. We'd take photos of the towering piles of packages. We'd work weekend shifts and have weekend pickups to make sure everything got out the door on time. I'd often write a blog post celebrating all of this.
As our business has evolved and retail in general has scaled back and spaced out the holiday shopping season (remember when stores would open on Thanksgiving?), we've adjusted our approach to similarly be a little more measured, a little more balanced, a little less chaotic.
Our volume has grown disproportionately in our spring and summer peak season, meaning a huge spike on Black Friday is out of the ordinary for the fall/winter and also less necessary. By starting our promotions earlier and dialing back the biggest ones (in particular combining huge discounts with free shipping), we've solved a bunch of problems all at once.
While our customers still get great deals, we're no longer shipping a ton of volume at low margins. We don't need to staff up, work late, work weekend shifts, or coordinate weekend package pickups. We also don't need to overstock inventory heading into a slower period over the winter.
The result is that we can all enjoy our holidays and set up the business for greater success heading into the winter and next year's peak season.
Bringing Package Tracking Data to Detailed Image's Shopping Cart
![]()
We recently launched a really nice feature for Detailed Image's shopping cart that filled in some holes in the customer experience and greatly improved our internal shipping data. We're now tracking the status of packages after they leave our warehouse using the FedEx API and USPS API.
Previously, our shopping cart's interaction with a customer's order ended after it was shipped. We'd send them an email with a link to the tracking number on FedEx.com or USPS.com. Their order status pages would show "Shipped" with the tracking number, and that would be the end of it.
Over the years it has become more common place to manage tracking and delivery information on the retailer's site (or using a third-party like Narvar).
Our system now checks on undelivered orders every few hours and updates the latest status and a few other details in our database, which enables us to do a bunch of cool things:
- Update those order status pages to show "Delivered" once a package has arrived.
- Display real-time tracking data on our website (we do a live API call when the page is loaded to ensure the latest information is present). This keeps customers on our site and allows us to prevent the tracking events in a clean, consistent manner along with added information from our system such as when the order was processed and picked up.
- Improve our contact form workflow so that certain types of issues, such as an incorrect item in a package, can only be submitted after delivery.
- Proactively reship orders when there's a damage, exception, or a package is lost.
- Study delivery speeds by service and/or geographic location with a simple query of the database. This missing piece of information can help us with everything from our checkout page delivery estimates to negotiating better rates with shipping providers.
- Send delivery emails when a package has arrived (we haven't done this yet).
We all shop online a lot. This was one of the few things lacking in our core shopping experience that we all felt we needed. When we mapped out the project and saw just how many "wins" there would be, it became much more of a priority.
Contact me
You can get in touch on LinkedIn or by emailing adam at our company domain.